RPM
Beyond the TPM limit, an RPM rate limit is also enforced, where the amount of RPM available to a model is set proportionally to the TPM assignment using a ratio of 6 RPM per 1,000 TPM.
RPM is not a direct billing component, but it is a component of rate limits. It is important to note that while the billing for AOAI is token-based (TPM), the actual two triggers in which rate limits occur are as follows:
On a per-second basis, not at the per-minute billing level.
The rate limit will occur at either tokens per second (TPS) or RPM evaluated over a small period (1-10 seconds). That is, if you exceed the total TPS for a specific model, then a rate limit applies. If you exceed the RPM over a short period, then a rate limit will also apply, returning limit error codes (429).
The throttled rate limits can easily be managed using the scaling special sauce, as well as following some of the best practices described later in this chapter.
You can read more about quota management and the details on how TPM/RPM rate limits apply in the Manage Azure OpenAI Service link at the end of this chapter.
PTUs
The Microsoft Azure cloud recently introduced the ability to use reserved capacity, or PTUs, for AOAI earlier this summer. Beyond the default TPMs described above, this new Azure OpenAI service feature, PTUs, defines the model processing capacity, using reserved resources, for processing prompts and generating completions.
PTUs are another way an enterprise can scale up to meet business requirements as they can provide reserved capacity for your most demanding and complex prompt/completion scenarios.
Different types of PTUs are available, where size of these PTUs is available in smaller increments or larger increments of PTU units. For example, the first version of PTUs, which we will call Classic PTUs, and newer PTU offerings, such as “managed” PTUs, size offering differs to accommodate various size workloads in a more predictable fashion.
PTUs are purchased as a monthly commitment with an auto-renewal option, which will reserve AOAI capacity within an Azure subscription, using a specific model, in a specific Azure region. Let’s say you have 300 PTUs provisioned for GPT 3.5 Turbo. The PTUs are only provisioned for GPT 3.5 Turbo deployments, within a specific Azure subscription, not for GPT 4. You can have separate PTUs for GPT 4, with the minimum PTUs described in the following table , for classic PTUs. There are also managed PTUs, which can vary in min. size.
Keep in mind that while having reserved capacity does provide consistent latency, predictable performance and throughput, this throughput amount is highly dependent on your scenario – that is, throughputwill be affected by a few items, including the number and ratio of prompts and generation tokens, the number of simultaneous requests, and the type and version of the model used. The following table describes the approximate TPMs expected concerning PTUs per model. Throughput can vary, so an approximate range has been provided:
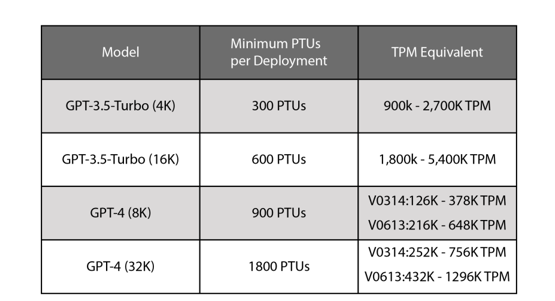
Figure 7.3 – Approximate throughput range of Classic PTUs
As you can scale by creating multiple (Azure) OpenAI accounts, you can also scale by increasing the number of PTUs. For scaling purposes, you can multiply the minimum number of PTUs required in terms of whatever your application or service requires.
The following table describes this scaling of classic PTUs:
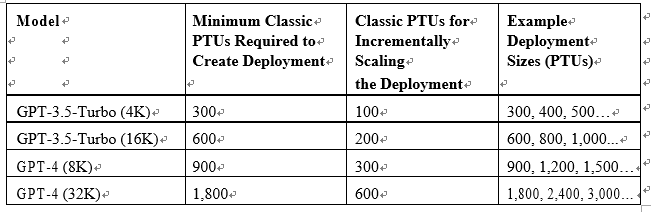
Figure 7.4 – PTU minimums and incremental scaling (classic PTU)
Note
The PTU size and type are continuously evolving. The two tables above are just to give a sense about the approximate scale of the PTUs with respect to TPMs and how it differs based on model and version. For more updated information, you can visit the Provisioned Throughput Units (PTU) getting started guide.
Now we have understood the essential components for scaling purposes like TPM, RPM and PTU. Now let’s delve into the scaling strategies and how to circumvent these limits with our special scaling sauce for a large-scale and global enterprise-ready application.