HTTP return codes
HTTP return codes, sometimes generically called “error codes” and briefly mentioned in the previous section, provide a way to validate. This is a standard web pattern many web developers will easily recognize.
Remember that when your application is sending prompts, it does so via HTTP API calls.
As described in the Retries with exponential backoff – the scaling special saucesection, you can use retries with exponential backoff for any 429 errors based on the APIM retry policy document.
However, as a best practice, you should always configure error checking regarding the size of the prompt against the model this prompt is intended for first. For example, for GPT-4 (8k), this model supports a maximum request token limit of 8,192 tokens for each prompt+completion. If your prompt has a 10K token size, then this will cause the entire prompt to fail due to the token size being too large. You can continue retrying but the result will be the same – any subsequent retries would fail as well as the token limit size has already been exceeded. As a best practice, ensure the size of the prompt does not exceed the maximum request token limit immediately, before sending the prompt across the wire to the AOAI service. Again, here are the token size limits for each model:
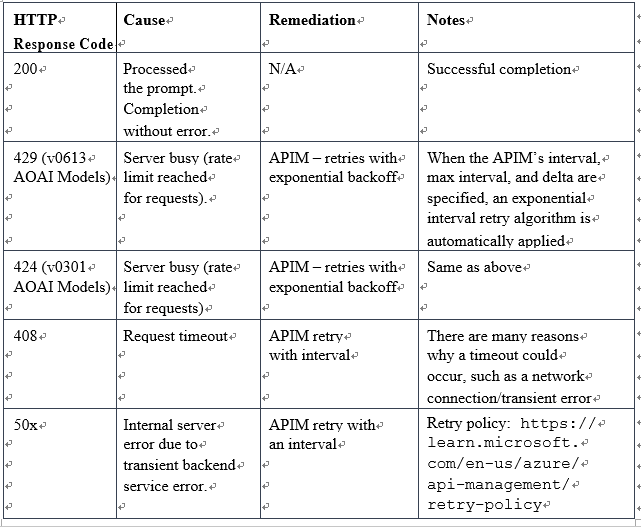

Figure 7.7 – HTTP return codes
The preceding table lists the most common HTTP return codes so that you can programmatically manage and handle each return code accordingly, based on the response. Together with monitoring and logging, your application and services can better handle most scaling aspects of generative AI service behaviors.
Next, we will learn about some additional considerations you should account for in your generative AI scaling journey.