Essential components of LLMOps
In this section, we will discuss some of the key components of LLMOps that entail the process explained previously:
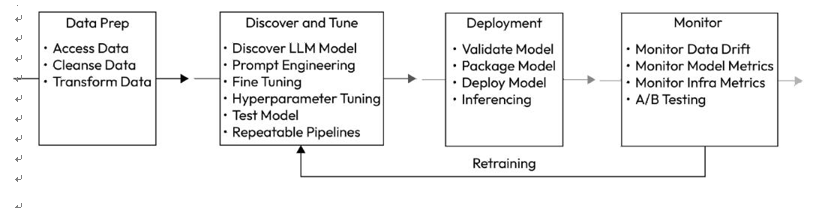
Figure 6.7 – The flow of an LLM lifecycle
The enterprise LLMOps strategy must include the following steps as a minimum:
Data preparation
- Initialization and data curation: This step facilitates the creation of reproducible and versioned datasets. It involves transforming, aggregating, and de-duplicating data, as well as developing structured and reliable prompts for querying LLMs. Additionally, exploratory analysis is performed to understand the nature of the data and enrich it with any necessary information.
Discover and tune
- Experimentation: Thisstep focuses on identifying the most suitable LLM solutions by researching and discovering LLMs that could match your use case. It involves auditing through rapid iterations of testing various techniques, including prompt engineering, information retrieval optimization, relevance enhancement, model selection, fine-tuning, and hyperparameter adjustments.
- Evaluation and refinement: This is the process that defines tailored metrics, and selecting methods of comparing results to them at key points that contribute to overall solution performance. This is an iterative process to see how changes impact solution performance such as optimizing a search index during information retrieval for RAG implementations or refining few-shot examples through prompt engineering.
Deployment
- Validation and deployment: This step includes rigorous model validation to evaluateperformance in production environments and A/B testing to evaluate new and existing solutions before deploying the most performant ones into various environments.
- Inferencing and serving: This step involves providing an optimized model tailored for consistent, reliable, low-latency, and high-throughput responses, with batch processing support. Enabling CI/CD to automate the preproduction pipeline. Serving is usually done with a REST API call.
Monitoring with human feedback
- Monitor models: Monitoring within an LLM or LLMOps, is a critical component to ensure the overall health of your LLM over a continued period of time. Items such as model data drift, which occurs when the distribution of the datasets used with LLM changes over time, can lead to model degradation and performance. This is especially true when doing any predictive analytics, as the input data may be incorrect, thus having a false outcome. Fortunately, there are features within commercial services, such as Azure Machine Learning, which help account for and monitor data drift.
The image below, sourced from Microsoft’s blog on LLMOps, depicts a dashboard that monitors a few evaluation metrics related to quality, such as groundedness, relevance, fluency, similarity, and coherence for generative AI applications, illustrating their changes over time:
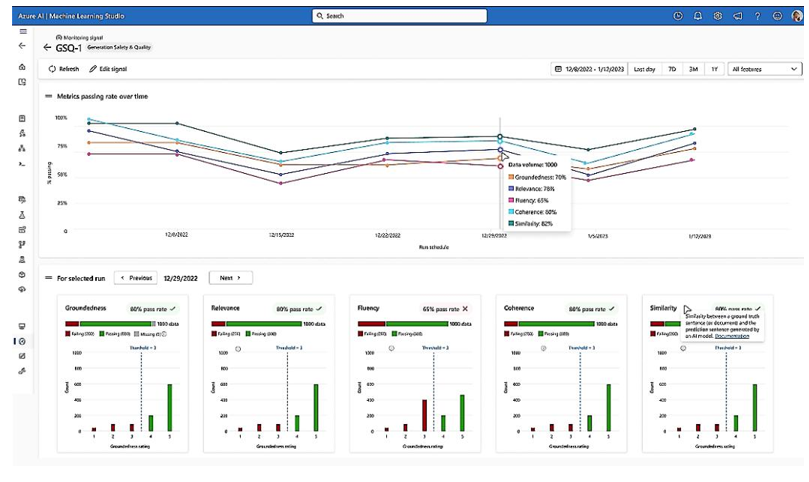
Figure 6.8 – An overview of LLMOps dashboard on Azure Prompt Flow
- Infra-monitoring: With any comprehensive operational plan, monitoring is always an included critical component.
The monitoring procedures cover tools and practices to assess and report on system and solution performance and health. Monitored areas include API latency and throughput (Requests per second and Tokens Per second) to ensure optimal user experience. This can be achieved through Azure API Management, which we discuss in the next chapter.
Metrics to track resource utilization, raising real-time alerts for issues or anomalies or for any data privacy breaches like jailbreak attacks, prompt injections, etc, and evaluating queries and responses for issues such as inappropriate responses. We discuss such metrics related to safe, secure, and responsible AI, in Chapters 8 and 9.
Finally, most modern monitoring systems can also automatically raise trouble and support tickets, for human intervention and review, for any alerts, anomalies, or issues.
Retraining
- Collecting feedback: Thiscritical step enables seamless mechanism for collecting user feedback or capturing user-provided data for insights, which is then used to enrich the validation datasets to improve the LLM solution’s performance.
The components and activities identified in the preceding list can be developed into repeatable pipelines. These pipelines can then be efficiently orchestrated into a coherent workflow, as previously discussed. By further enhancing operational efficiency, this orchestrated workflow can be automated and seamlessly integrated with continuous integration/continuous deployment (CI/CD) workflows. Such pipelines can be easily developed in Python using frameworks, such as Langchain or Semantic Kernel, and then orchestrated and automated on Azure Prompt Flow.